
Migra
![]()
Migra is an ETL tool made as an exercise with technologies such as Scala and the Akka framework.
It aims to implement the most important functions of an ETL tool but keeping the runtime configuration simple and lightweight, trying to make it generic enough to cover many use cases, but also keeping the design easy to extend to create custom processors.
How does it work?
I tried to keep the usage as simple as possible: to run an ETL process you just have to create a “descriptor” (i.e. a file with instructions) with the following content:
{
"extract": [
{
"type": "ExtractorType",
"config": {
"key": "value"
}
},
{
"type": "ExtractorType",
"config": {
"key": "value"
}
}
],
"consume": [
{
"type": "ConsumerType",
"config": {
"key": "value"
}
},
{
"type": "ConsumerType",
"config": {
"key": "value"
}
}
]
}
Within the extract section you will put a description on how the data will be extracted
from various data sources, effectively building the final results, that will be then fed
into all the consumers that are put into the consume section.
The below image gives the idea of how the process works.
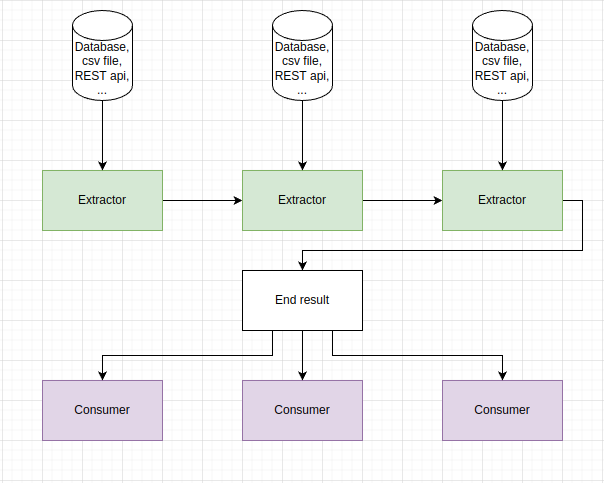
Some basic extractors and consumers are provided, such as database connectors supporting all major SQL databases (if there’s a JDBC driver for it, then Migra will support it), HTTP connectors that can retrieve or send JSON to REST APIs, script connectors, that will allow you to create your own logic by just writing some simple code.
Concept
The architecture is fairly simple and is composed by two main components:
Extractor and Consumer.
An extractor takes the role of both E and T in the ETL process:
An extractor will extract data from a data source, but can also be used to
transform the data coming downstream using input data to interpolate it from
another datasource. Think of it as a flatMap operation where each data coming
from the previous step is used to configure a new extractor which in turn will
generate another sequence of data.
Consumers are the L phase of the ETL process. They represent terminal operations and are usually used to load data into another place. A process can have any nymber of consumers set, and they will all run in parallel taking data from the last extractor.
Mode of use and plan for the long term
Currently, Migra can only be run as a standalone application, and only after it’s been built from the sources.
I am planning to release Migra as a standalone application that will support two operating modes:
- standalone, to run single processes via command line
- server, to create an environment that allows multiple users to connect, create and execute their processes.
Repository
You can find the repository with build and usage instructions here: https://github.com/LukeDS-it/migra
License
Migra is licensed under the MIT license, for now. It means you can use it and modify it, but I won’t take any responsibility for anything that happens to your data, your PC, your job if you misuse it or if it doesn’t work as you’d expect. For more info read the MIT license here